





Hugging Face
Hugging Face is a leading company in the field of natural language processing (NLP) and machine learning, known for providing a vast collection of pre-trained models and tools for a wide range of tasks.
Is it easy to deploy a Hugging Face model?
Deploying a model from Hugging Face, or any large language models, can vary in complexity depending on the size of the model and the specific requirements of your application. Here are some factors and steps to consider:
1. Hardware Requirements
- Smaller Models : Can often be run on consumer-grade GPUs with enough memory (e.g., NVIDIA RTX 3090 with 24GB VRAM).
- Larger Models : Require more powerful hardware, such as multiple high-end GPUs or specialized hardware like TPUs.
2. Software Setup
- Frameworks: Hugging models are typically implemented using popular deep learning frameworks like PyTorch or TensorFlow.
- Dependencies: Ensure you have all necessary libraries and dependencies installed. This may include CUDA for GPU support and other libraries for handling data and preprocessing.
3. Model Access
- Pre-trained Models: Obtain pre-trained Hugging Face models from Hugging Face or other repositories. These models are often available in formats compatible with PyTorch or TensorFlow.
- Fine-tuning: If you need the model to perform specific tasks, you might need to fine-tune it on your own dataset. This involves additional training which can be resource-intensive.
4. Deployment Environment
- Local Deployment: Suitable for development and testing. Requires a machine with a compatible GPU.
- Cloud Deployment: For production use, deploying on cloud platforms (like AWS, Google Cloud, Azure) that provide powerful GPUs/TPUs is common. These platforms also offer scalability and easy management.
5. Inference and API Setup
- Inference Pipelines: Set up an inference pipeline to process input text, run it through the model, and generate output.
- APIs: Create APIs (e.g., RESTful APIs using Flask or FastAPI) to serve model predictions to applications.
6. Optimization
- Quantization and Pruning: Techniques like quantization (reducing the precision of the model’s weights) and pruning (removing redundant parts of the model) can help reduce resource requirements and improve inference speed.
- Batching and Parallelization: Efficiently batch inputs and leverage parallel processing to optimize performance.
7. Monitoring and Maintenance
- Monitoring: Implement monitoring to track the performance and resource usage of the deployed model.
- Updating: Regularly update the model and dependencies to ensure compatibility and performance.
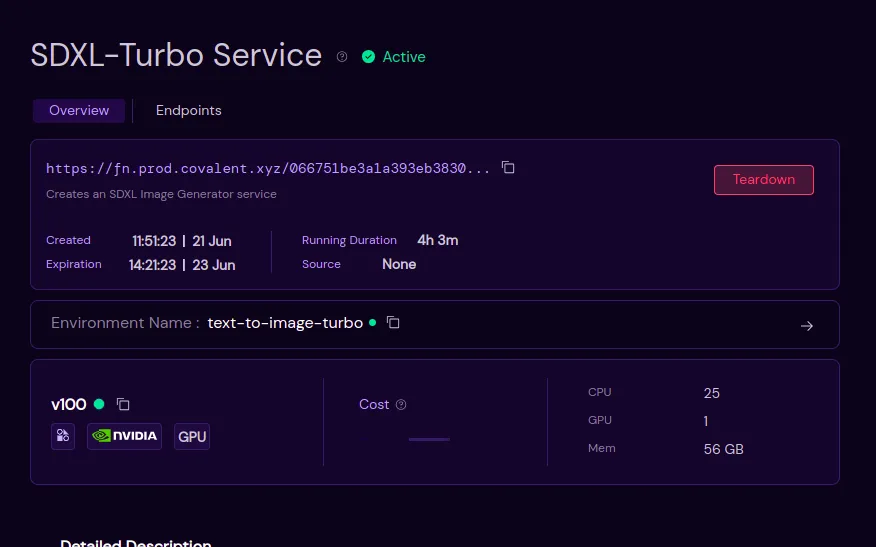
Seamless AI model deployment with Covalent
Function serve
I was thinking of explaining what, how, and why then remembered that documentation has all you need to know
Serving a Lightweight Text-to-Image Model
Here is a live app that uses SG161222/RealVisXL_V4.0 runs on NVIDIA V100 and is served via Streamlit